The Long Road to Web Standards: Design Reboot (Part 3)
In the weeks leading up to the launch of this blog, I had a single colour in mind – a particular shade of green that proved surprisingly fickle to catch and indeed, I was envious of those who had found it.
In case you were wondering, here is that colour – ![]() Doesn’t look that important does it? But if you are interested in web design, that colour is a holy grail – for it means a page you created is Valid XHTML. And yes, I have reached this hallowed place as well. I flaunt this badge of honour elsewhere on this blog. Several factors combined to make this journey a remarkable difficult one, but let’s start at the beginning.
Doesn’t look that important does it? But if you are interested in web design, that colour is a holy grail – for it means a page you created is Valid XHTML. And yes, I have reached this hallowed place as well. I flaunt this badge of honour elsewhere on this blog. Several factors combined to make this journey a remarkable difficult one, but let’s start at the beginning.
When I finally decided that I needed to radically overhaul my blog, I realized I needed something to hold as a standard for each design decision – what would be the basis by which I would add or remove content? The easiest answer was Web Standards – the promise of a website that would remain usable and accessible in the years to come. That decision was quickly ratified when I realized my old blog had a staggering 91 errors – and they started right from the meta-information.
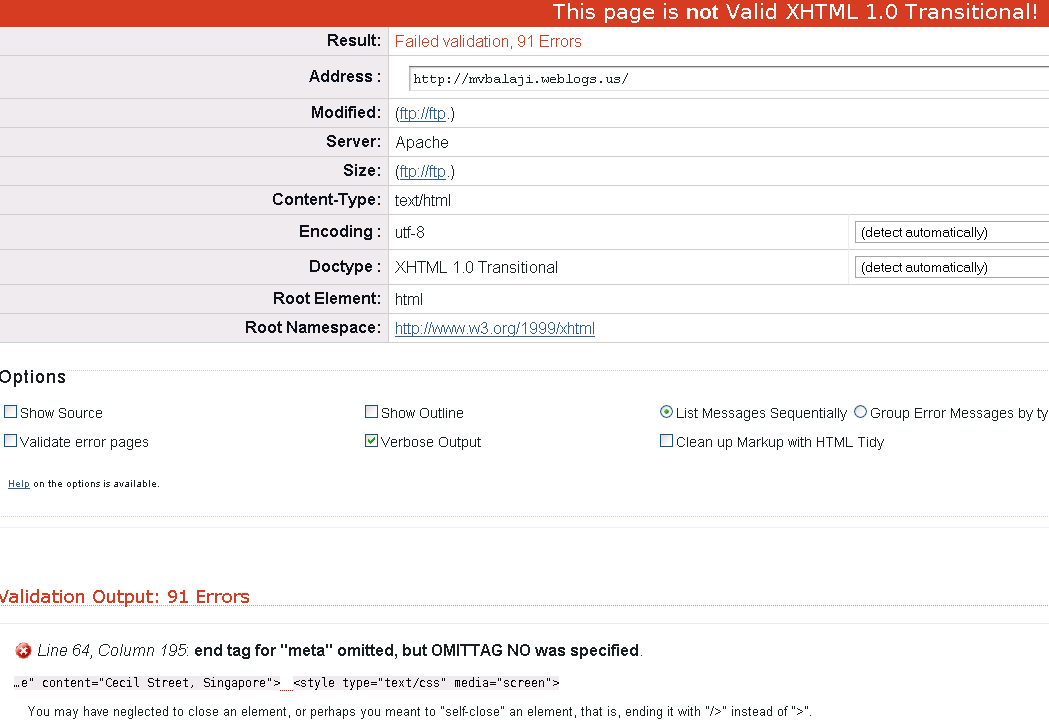{kind=link}
I read the books, subscribed to the right blogs and was a believer – but almost right away, the first problem appeared.
Strict XHTML is well too strict.
When you install WordPress for the first time, the default look of your blog is based on a theme called “Kubrick“. Typically your next step is to get on the WordPress Theme Browser and find a replacement because quite frankly Kubrick is boring. Once you find a theme that catches your eye, you activate a theme and everything is fine and dandy. Well not quite – you see, most themes approved by WordPress start with this line:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
See that bit that says XHTML 1.0 Strict? – that’s sort of the Greek God of Web Standards for HTML: pure and perfect. Which as it turns it out is not so great for us clumsy mortals. XHTML 1.0 Strict frowns on the use of presentational elements – for example, the fact that I used italics for the words presentational elements is frowned upon under XHTML 1.0 Strict. XHTML 1.0 Strict essentially implies that the document contains only content – the rules on how that content is to be presented are controlled through the use of CSS. So the sentence at the beginning of this part of the post?
Strict XHTML is well too strict
The HTML for that sentence goes like this:
<strong>Strict XHTML is well <u>too</u> strict.</strong>
The fact that I underlined the word “too” makes it an invalid XHTML 1.0 Strict document. Don’t believe me? Look at these two pages – Page 1, Page 2. They look identical, but Page 1 fails validation – You can verify that statement by clicking on the link that says “Check Validity” at the end of each page. So, it’s very likely that if you use a lot of formatting in your blog posts and are using a off the shelf theme, your site would fail validation.
Am I saying that XHTML 1.0 Strict doesn’t make sense? No – if a website has a lot of static content, or content that’s served progamatically, XHTML 1.0 Strict is the way to go.
For content that’s written by humans though, XHTML 1.0 Transitional makes a lot more sense. It’s a lot more forgiving that XHTML 1.0 Strict, but it still keeps you on the high road when it comes to web standards. It worries me therefore, that XHTML 1.0 Transitional is seen as a deprecated standard – future standards such as XHTML 2.0 and HTML5 are even more unforgiving. Is allowing 5 formatting elements and about 20 attributes to remain such a significant issue?
Just because it looks right, doesn’t mean it is right
Remember those two pages I had linked above as examples for the XHTML 1.0 Strict discussion and then said “They look identical, but one isn’t valid”? No? Well now that I’ve told you, you should 🙂 . This really was the biggest source of frustration for me when trying to get my site validated – HTML as a language, and the programs that “compile it” (browsers, search engine robots etc.) are far too forgiving when it comes to errors.
Let’s look at some more example pages – shall we? This page shows a heading, then a list of items using the following bit of HTML:
1: <ol>
2: <li>
3: <h3>The Gnome Plan</h3>
4: <ul>
5: <li>Collect Underpants</li>
6: <li>???</li>
7: <li>Profit!</li>
8: </ul>
9: </li>
10: </ol>
A quick breakdown – there’s a numbered list (the ol-li code at the top), Inside this numbered list, there’s a bulleted list (the ul-li code starting from line 4). Happily, this page is Valid XHTML 1.0 Strict. Now let’s look at another chunk of code:
1: <ol>
2: <li>
3: <h3>The Gnome Plan</h3>
4: <ul>
5: <li>Collect Underpants</li>
6: <li>???</li>
7: <li>Profit!</li>
8: </ul>
9: </ol>
This code fails validation – catastrophically. Try validating this page for proof.
Now if you are a web designer or HTML programmer, you already know why the second chunk of code is crap. But for those of you who aren’t (like me) here’s the answer – Code Example #2 is missing the li from Code Example #1 at line 9.
But what if this example was nested inside HTML that was 200 lines long, how easy do you think it would be to spot? Even more frustrating, unlike regular programming code this bit of code would compile (display) properly! It’s enough to drive non programmers like me to drink ( as I did many times 😛 )
The reason for this is because browsers follow Postel’s Law, which states in part “Be Liberal in what you accept from others”. As Mark Pilgrim so beautifully demonstrates in his “Thought Experiment“, the alternative is far worse. But what if you wanted your browser to be unforgiving and point out every error you make? After all Postel’s Law also states “Be conservative in what you do”. Sadly, there is no easy way to achieve this. As John Gruber points out in this article, snippets of HTML cannot be validated as HTML is a document format (emphasis Gruber’s). In other words, you would have to build a complete document with all the nessecary header and DOCTYPE information and only then could you determine whether you have valid markup in your pages.
Browsers can give you more immediate feedback though – you see, most CMS software (and other packages) serve your document as “text/html” document and this tells the browser “Hey! Go easy on this page – it’s probably not semantic”. If on the other hand you could get your software to serve those same pages as “xhtml+xml”, any error would result in the Yellow screen of death. Unfortunately, making that change is non-trivial and so we must rely frustratingly, on writing complete pages and then hoping it works.
Getting CSS right is easy, so why do so many websites get it wrong?
The next part of Web Standards that I had to worry about was CSS Validation. This as it turns out, is relatively trivial to accomplish. CSS validation really is more about grammar than anything else – close your brackets, don’t forget the semi-colons and you’re done. Of course, one could argue that HTML validation is also grammar – closing your tags and so on. The difference is – most of the HTML content that’s generated is dynamic and constantly changing, CSS on the other hand is almost carved in stone.
That’s understandable – after all, in the world of web standards, CSS alone defines what your site looks like and how often do you change that? Sure you make tweaks here and there, but radical overhauls are few and far between. So it’s surprising then how often I see this in my browser window:
![]()
That little red exclamation mark comes from a Firefox extension called the “Web Developer Toolbar” and it’s telling me there’s a CSS error in the site I’m visiting. The usual culprit? Typing errors – forgetting a semicolon or a closing bracket, “buttom” instead of “bottom” (tee-hee) and so on. Occasionally though, I do see errors because CSS hacks for one browser (coughIEcough) make their way into the main stylesheet. When there exists a simple way to serve different stylesheets for different browsers, why would you opt for the more confusing choice? Um I do know the answer to this one.
It doesn’t end on Day One
Think it’s over because your site validated when you first launched? Ha. Have I got news for you. If you weren’t paying attention, your site is probably rife with errors by now. The culprit – code from other websites that you embed.
Case in point – Let’s say you wanted to embed a slideshow of your photos on Flickr in your blog. You go to this page, follow the instructions and the end you get a big chunk of code to put into your blog template. Plug that in and you can wave your green signal (this one – ![]() ) goodbye. The problem comes from the fact that the code that Flickr provides ships with angle brackets by default instead of the HTML entity for angle brackets (this page explains it in more detail) and since this is being embedded in the body of the page, it breaks the validation.
) goodbye. The problem comes from the fact that the code that Flickr provides ships with angle brackets by default instead of the HTML entity for angle brackets (this page explains it in more detail) and since this is being embedded in the body of the page, it breaks the validation.
Moral of the story? Be careful about the code you include. As I blogged about earlier, treating your blog as a clearing-house for your online identity is probably not a good idea – from a design and standards perspective.
Can your site take a bullet?
Obviously, if someone actually tried to shoot the server where your site was hosted, bad things would happen. No, I’m taking about what happens when the people who visit your site do unexpected things – like turn off all images, or block javascript. Is your site still functional? For example, if you have white text for your navigation links on a black image background, your navigation links might disappear into the background if the visitor has blocked all images!
Or your page navigation is fancy AJAX refreshes using Javascript – what happens if the user blocks javascript? Clicking on a button does nothing!
This to me is the hardest part of the journey because you have to think of all the things that can go wrong. Thankfully, there is some help in the form of Dan Cederholm’s book. Again, the Web Developer Toolbar is of tremendous help here. No matter how much you test, the reality is that even now, there are visitors to your site who have given up because something went wrong. So it goes.
Your point being…?
Talk about something being TL;DR eh. The payoff of Web Standards is “findability”. Your content is accessible and understandable to all the visitors to your site – humans, search engine robots, site-scrapers the whole lot. I’m not advocating focussing on standards above content. Content is king yes, but if your content is buried in a mass of impenetrable markup – it may as well be 100 monkeys banging on typewriters.
PS: I know that XHTML validation for the blog fails right know, thanks to some of the embedded formatting in this post. I’m treating it as a temporary problem 🙂 Fixed! I’ve stripped out the custom styling for the code samples for now as that was causing the problem. Custom styles will be back once the WLW plugin I’m using gets a new build that fixed these problems.